인공지능,딥러닝,머신러닝 기초
[인공지능 개론] DL
풍요 평화 만땅 연구원
2022. 10. 18. 17:45
CNN
- padding @ convolution
- 영상 끝자락에서filter kernel에 기여하는 boundary pixel들을 center pixel로 값을 뽑기 위한 방법
- Valid & Same
- valid : no padding
- Same : zero padding
- 패딩은 합성곱 연산을 수행하기 전 입력데이터 주변을 특정값으로 채워 늘리는 것을 말함
- 패딩을 사용하는 이유는 패딩을 사용하지 않을 경우 데이터의 Spatial크기는 Convlayer지날때마다 작아지게 되므로, 가장 자리의 정보들이 사라지는 문제가 발생하기 때문에 패딩을 사용함
- Stride @ convolution
- Sliding window 방식의 filter convolution대신에 점핑해서 convolve할 때
- 입력데이터에 필터를 적용할 때 이동할 간격을 조정하는것, 즉 필터가 이동할 간격을 말함
- 스트라이드 또한 출력 데이터의 크기를 조절하기 위해 사용함
- Pooling
- output feature map의 모든 data가 필요하지 않기 때문
- inference(추론)을 하는데 모든 data가 쓰이지 않을 것
- 효과
- network이 표현력이 줄어들어 Overfitting억제
- computation이 줄어들어 hardware resource(energy)를 절약, speedup
Seq2Seq와 Attention
- Sequence to Sequence 는 어떤 Sequence(연속된 데이터)들을 다른 Sequence로 Mapping하는 알고리즘임
- 가장 알기 쉽게, 한글로 작성된 문장을 영어로 작성된 문장으로 번역하는 Translation이 가장 많이 언급되는 Application이라 할 수 있음
- Seq2Seq는 크게 정볼르 압축하는 Encoder부분과 이를 통해 새로운 Data를 생성해내는 Decoder부분으로 나눠져 있음
- 번역으로 예를 들면, 압축되는 정볻르은 '단어 및 어간'에 관한 정보들로 표현될 수 있을 것임
- 많은 시계열 분석에 LSTM을 적용할 때, 잘 작동하는 경우가 많지만, LSTM의 Encoder에서 Decoder로 들어가는 과정에서, 전달되는 정보에서 소실되는 시간 정보들이 생기게 되엇음
- 예를 들어, output Sequence를 얻기 위해선 단어의 Mapping만으로 충분한 것이 아니라, Keyword와 중요한 부분에 대한 정보가 필요함
- 이를 위해서 나온 개념이 Attention임
- 쉽게 설명하자면 'Input Data의 이부분(Time Step)이 중요해요!, 집중해주세요!'라고 하는 수치들을 같이 output으로 넘겨주는 방식임
- 따라서 output sequence를 생성해내는 매 Time Step마다 이전 input time step들을 다시 보고 중요하다는 부분을 참고해서 output을 생성한느 방식임
- 말만으로는 매우 직관적이고 좋은 방법이지만, 구현으로 ㄷ르어가면 어떻게 '이 부분이 중요해요'라는 수치를 만들지를 알아야함
Transformer
- Encoder
- RNN, LSTM의 약점으로 많이 언급되었떤 것은 단어를 순차적으로 입력받아서, 이를 계싼하기 때문에 병렬처리가 어렵다는 점이였음
- 하지만 순차적으로 입력받는 것이 각 input위치정보를 반영할 수 잇게 해주었음
- Transformer는 순차적으로 Data를 넣는 것이 아니라, Sequence를 한번에 넣음으로써 병렬처리가 가능하면서도, Attention등의 구조를 통해 어떤 부부닝 중요한지를 전달하여, 위치정보를 반영할 수 있게 됨
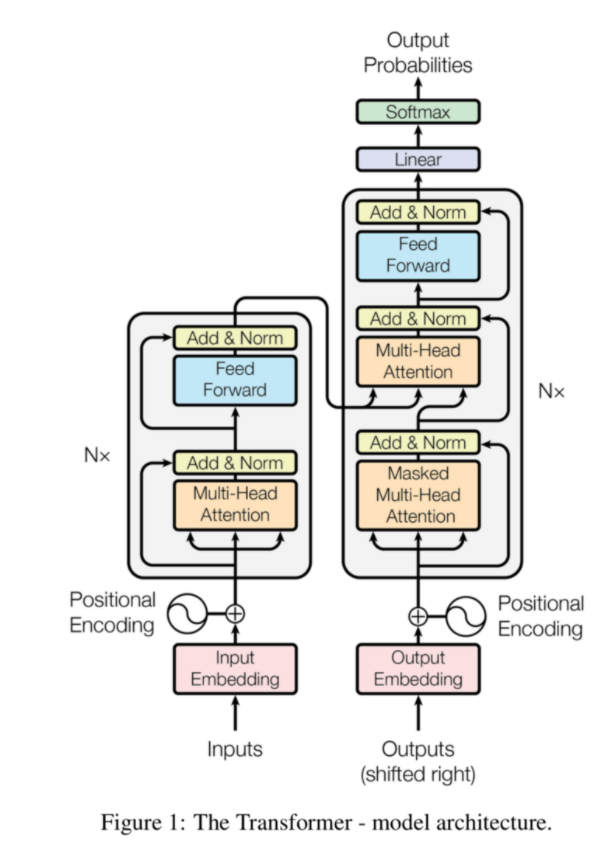
- 위 그림에서 먼저 Embedding단계가 있음
- Embedding은 다른 알고리즘에서도 많이 쓰는 방식으로, data를 임의 의 N-dimension data 로 만들어주는 단계임
- 본격적인 Transformer은 Positional Encoding으로 시작함
- 앞에서 설명했듯이, RNN이나 LSTM처럼 순차적으로 데이터를 넣어주지 않기 때문에, 데이터의 위치정보를 전달해주는 방법이 필요하며 positional encoding이 이 역할을 담당함
- Positional Encoding은 'Sequence내에서 해당 정보의 위치정보'와 'Embedding된 데이터'를 사인함수와 코사인함수 형태로 만들어서 다음 Layer의 input으로 전달하게됨
- 쉽게 설명하자면, Embedding을 할 때 위치정보까지 함께 넣어주자는 내용임
- 이렇게 정리된 Input data 들은 본격적으로 Encoder로 들어가게됨
- Encoder는 Multi-head Self Attention / Add&Normalize / Position-wise FFNN라는 모듈들로 구성됨
- Self-Attention은 Encoder로 들어간 벡터와 Encoder로 들어간 모든 벡터를 연산해서 Attention score 값을 구함
- Attention 함수의 Query (Q), Key (K), Value (V)를 의미하는 Weight 행렬과 'scaled Dot-Product Attention'방식으로 연산하여 Attention Value Matrix (a)를 만들어냄
- 이 과정에서 d_model개의 차원을 num_heads로 나눠지는 갯수만큼의 그룹으로 묶어서 d_model/num_head 개의 Attention value matrix를 뽑아냄
- Add & Normalization은 Residual Connection과 layer Nomralization.-> 연산을 한 부분과 안 하는 부분이 합쳐지도록 만든 것
- 이렇게 함으로써, 층이 쌓일 때, 뒤쪽까지 학습이 잘 전달되지 않는 것을 방지할 수 있음
- 이렇게 Multi-head Self Attention / Add & Normalize / Position-wise FFNN라는 모듈들로 구성된 Encoder 함수를 N층 쌓고 여기서 나온 데이터들이 Decoder로 흘러감
B. Decoder
Decoder로 Encoder처럼 Positional Encoding과 Multi-head Self Attention을 한다는 점은 비슷하지만, 크게 두가지의 차이가 있다. Multi-head Self Attention에 Masked가 들어갔다는 점이 첫 번째 차이점인데, Decoder는 현재까지 들어온 데이터 보다 미래의 데이터를 보면서 학습하면 안 되기 때문에, 미래에 해당하는 Attention score들에는 매우 작은 음수값 (-1e9)을 넣어서 이 부분을 Masking해버림