04. COVID-19분석 실습 : 전처리과정1
<과정>
1.데이터 기초정보 살펴보기
-파일읽기 : pd.read_csv() 함수사용하여 => DataFrame으로 자동으로 가져온다
*
import pandas as pd
import numpy as np
data=pd.read_csv("data/lending-~.csv",sep=",",dtype='unicode')
2.탐색 & 전처리
-먼저 각 컬럼들을 살펴보기
-NaN 값만 골라내고, 해당행을 제거해야한다
*df.dropna(how="any") : NaN을 포함하는 행들을 제거한 df를 가져올수있다
*any 는 행의 성분에 NaN이 하나라도 있으면 그 행을 제거 라는 뜻이다.
*how인자에 "all"이 있다면, 행의 성분이 모두 NaN일때 제거한다는 뜻이다
-NaN대신 다른 값을 대입 : df.fillna(value=5.0)
-NaN인 성분만 True를 뽑아내주는 => df.isnull()함수 사용
-행또는 열 삭제 :
*행을 삭제하기 앞서, 행의 index에 접근을 먼저해야한다.
*20160701=>2016-07-01 바꾸는 방법 : pd.to_datetime("2016.07.01")
=>df.drop(pd.to_datetime("20160701"))=> 2016-07-01인덱스를 가진 행이 사라진 것을 확인
*다른 방법 : df.drop("F", axis=1) : drop()함수의 인자는 기본적으로 행의 인덱스를 가져야 함 / 이를 상쇄하면서 들 어간 인자가 "컬럼명"이라는 것을 명시해주기 위해 :axis=1
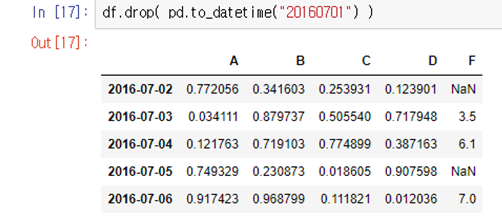
-2개 이상의 특정행을 삭제하고 싶다면? : df.drop()인자로 [리스트]형태로 넣어서 삭제
*df.drop([pd.to_datetime("20160702"),pd.to_datetime("20160704")])

-df.shape : (행,열) 크기를 출력
=> df.shape
-df.info : 데이터 df의 정보 출력
=> df.info()
-df.describe():요약통계량 확인하기 //mean(),max(),median()등 개별함수를 사용하여 통계량을 계산할수도있다
-df['gdppercap'].median() : .median()함수를 이용하여 gdpPercap컬럼의 중앙값(median)을 출력
-결측치 처리 방법론
3. 결측 데이터의 원인 및 각각의 원인에 따른 처리 방법론
[그림1]에서 확인했듯이 결측치는 3개의 변수 Cabin, Age, Embarked에서 있었고 각각 결측치의 비율은 77%, 19.8%, 0.002% 입니다. 위에서 말했듯 Cabin의 경우 결측치가 생긴 이유는 사물함이 존재하지 않아서 일 가능성이 높고, Age와 Embarked는 MCAR 가정에 따라서 임의로 누락 되었을 가능성이 높습니다. Cabin의 경우 존재하지 않아서 결측치이니깐 위에서 hasCabin처럼 새로 변수를 만들어주는것이 좋고, Age와 Embarked의 경우는 다른 변수와의 관계를 통해서 결측치를 처리해주는것이 좋습니다.
보통 결측치를 처리할 때는 hair et al.(2006)에 따르면 아래의 표와 같이 처리해준다고 합니다.
|
결측치 비율 |
처리 방법 |
|
10% 미만 |
제거 or 어떠한 방법이든지 상관없이 Imputation |
|
10% 이상 20% 미만 |
hot deck , regression , model based method |
|
20% 이상 |
model based method , regression |
[표1] 결측치의 비율에 따른 처리 방법
위의 방법론에 따라 저희는 Age는 model based method를 이용하여 채워 넣고(다중대체 사용) Embarked는 다른 변수와의 관계을 이용하여 합리적 대체를 하겠습니다. 위의 실습자료에서는 제거의 경우는 적합하지 않아서 방법론만 설명하겠습니다.
*참고 싸이트 :
KNN Algorithm