2022. 7. 7. 12:14ㆍAI study
1. ML 에서 평가?
: 머신러닝 프로세스는 데이터 가공/변환, 모델 학습/예측, 그리고 평가로 구성 됨
- 일반적으로 성능 평가 지표는 회귀의 경우 실제값과 예측값의 오차 평균값에 기반 (ex) MAE, MSE
- 분류 평가 방법에는 이 데이터가 얼마나 정확하고 오류가 적게 발생하는 가에 기반하지만, 단순히 이러한 정확도(accuracy)만으로 판단했다가는 잘못된 평가 결과에 빠질 수 있음
- 정확도(accuracy)는 불균형(imbalanced)한 레이블 값 분포에서 모델의 성능을 판단할 때 적합하지 않음
- 따라서 여러가지 방법을 다양하게 활용해야함
- 정확도(accuracy)
- 오차행렬(Confusion Matrix)
- 정밀도(Precision)
- 재현율(Recall)
- F1스코어
2. ML 분류 모델 평가 방법
A. 정확도(accuracy)
- 정확도는 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표
- 정확도(Accuracy) = (예측 결과가 동일한 데이터 건수) / (전체 예측 데이터 건수)
- 장점: 직관적으로 모델 예측 성능을 나타내는 평가 지표
- 단점 : 이진분류인 데이터 특히, 불균형(imbalanced)한 레이블 값 분포의 경우엔 적합하지 않음
B. 오차행렬(confusion matrix)
- 이진 분류에서 성능 지표로서 잘 활용되는 오차 행렬은 분류 모델이 얼마나 헷갈리고있는지 함께 보여주는 지표

- T는 True를 의미하며, F는 False를 의미한다. / True는 예측값과 실제값이 같은것이며, False는 예측값과 실제값이 다름을 의미한다
- P는 Positive를 의미하며, N은 Negative를 의미한다. /즉, 예측값이 부정(0),긍정(1)을 의미한다.
- 정확도를 오차 행렬로 표현 한 수식
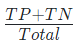
C. 정밀도(Precision)와 재현율(Recall)
- 정밀도(Precision) : Positive로 예측한 경우 중 실제로 Positive인 비율, 즉 예측값이 얼마나 정확한가 ( 예측한 경우 -> 실제 결과와 동일한 경우)

- 재현율(Recall) : 실제 Positive인 것 중 올바르게 Positive를 맞춘 것의 비율 이다다, 즉 실제 정답을 얼마나 맞췄느냐
*예시)
- 암 검사를 위해 병원을 찾아온 사람에게 암여부를 예측할때에는 재현율이 중요하다, 즉 실제로 암인데 암이 아니라고 예측하면 큰일나기 때문
- 메일이 왔는데 스팸메일여부를 판단하는 것은 정밀도가 중요
- 정밀도 계산을 위해서 precision_score()를, 재현율 계산을 위해 recall_score()를 API로 제공
- sklearn.metrics.classification_report 를 사용하면 정밀도, 재현율을 한번에 확인할 수 있다.
from sklearn.metrics import classification_report
print(classification_report(y_val, y_pred))
D. F1-Score
- F1 Score는 Precision과 Recall의 조화 평균으로 주로 분류 클래스 간의 데이터가 불균형이 심각할때 사용함
- 높을 수록 좋은 모델
- 장점 : 데이터 분류 클래스가 균일하지 못할때 사용
from sklearn.metrics import f1_score
pred = pipe.predict(X_test)
f1 = f1_score(y_test, pred)
'AI study' 카테고리의 다른 글
| Contour features (0) | 2022.08.13 |
|---|---|
| ML이나 image processing에서 grayscale image를 사용해야 하는 이유 (0) | 2022.08.13 |
| Random Forest vs Extra Trees (0) | 2022.07.07 |
| 서포트 벡터 머신(Support Vector Machine) _건물 에너지 사용 예측ML study (0) | 2022.07.06 |
| [영상 성능 분석] (0) | 2022.06.22 |